Privacy vs. Accuracy: Setting Realistic Expectations for Your Home LLM

Hosting your own Large Language Model (LLM) locally with tools like Ollama is a game-changer for digital privacy. It lets you run an interactive voice chatbot for your smart home (like Home Assistant) or have a powerful, private AI assistant right on your desktop via interfaces like Open WebUI. Your data stays within your walls, safe from corporate servers.
But when your super-private chatbot confidently spouts a complete fabrication, you have to ask: What's really going on with these local models? The answer lies in understanding what an LLM actually is and what it isn't.
The LLM Myth: Not a Super-Wikipedia
Most users run into frustration because they fundamentally misunderstand LLMs (like the ones powering ChatGPT, Grok, or Claude). We expect them to be a vast, reliable "knowledge vault"—a definitive database of facts. When they "hallucinate" (confidently generate false or invented information), it feels like a failure.
The Reality: A Statistical Pattern-Matcher
In reality, LLMs are not search engines or encyclopedias. They are sophisticated statistical pattern-matchers or next-token predictors.
- They're trained on an enormous dataset of human text (books, websites, code).
- They learn the probability of one word or concept following another.
- When you ask a question, the LLM doesn't "recall" a fact; it starts completing the sequence based on the most statistically likely words that would follow your prompt, aiming for text that sounds fluent and coherent.
This is why they excel at creative tasks, ideation, and summarizing—tasks based on pattern recognition. For reliable facts, you must treat their output like a draft: always cross-reference with verifiable sources. This is exactly why many online AIs use Retrieval-Augmented Generation (RAG), which pairs the LLM with an external search engine for real-time fact-checking. A core LLM, local or otherwise, is a generative tool, not an oracle.
The Home Hosting Reality: Vetting Your Local Model
When selecting a model for daily use on a home server, the first hurdle is simple: hardware compatibility.
- Constraints: Does the model fit within the server’s limitations (CPU, GPU, VRAM, and disk space)? This immediately slashes your options.
- Performance: For the models that do fit, performance is often comparable, especially if they can run entirely within the video card's memory.
After narrowing the field based on hardware, we ran a "Sanity Test" on a variety of local models, including llama3.1:8b, llama3.2:3b (Meta), and mistral-nemo:12b (Mistral AI). All three ran smoothly with Home Assistant and Ollama, but could they actually be useful?
The test involved a mix of basic knowledge, math, and logic questions:
- Facts: "What is the capital of France?" and "Who was the first president of the United States?"
- Math: "What's the square root of 81?" and "What's 22/7?"
- Logic: "There are three killers in a room. Someone enters the room and kills one of them. Nobody leaves the room. How many killers are left in the room?"
The Ultimate Litmus Test: The Acid Question
To truly gauge the depth of a model's knowledge—and how gracefully it fails—we used a final, fun, but obscure request:
"Write a one-paragraph summary of the 1977 cult classic comedy, 'The Kentucky Fried Movie.'"
We already know an unaugmented local LLM will likely hallucinate. The goal isn't to get the right answer, but to see how badly it fabricates the details. It's the perfect test because the correct information isn't widely repeated across the internet like facts about a major movie, forcing the model to rely on its internal, probabilistic patterns.
Local LLM Responses (llama3.1 and mistral-nemo)
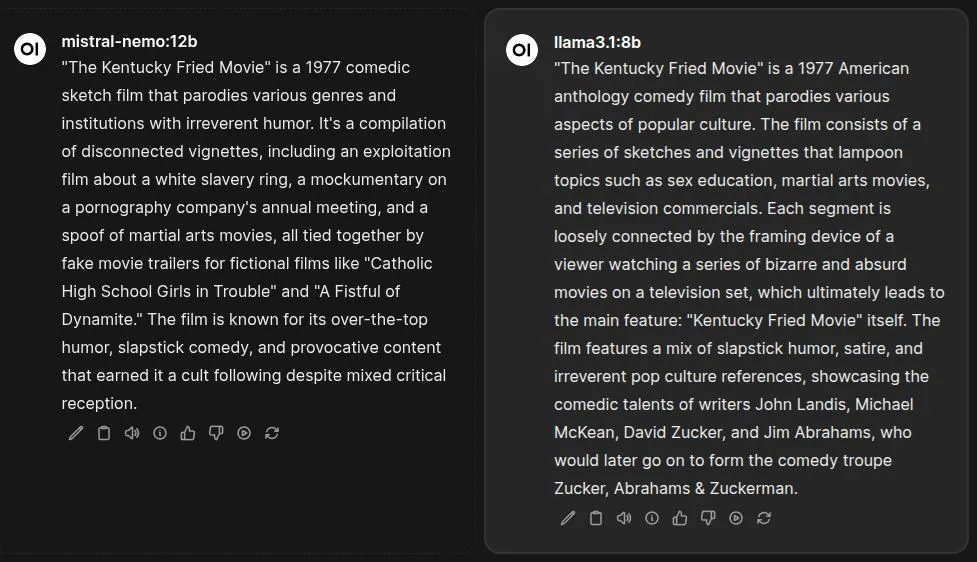
In our side-by-side test using the Open WebUI, both llama3.1 and mistral-nemo failed to produce a fully accurate summary. The key takeaway: for niche or less-documented topics, be ready for invention.
Take a look at the results below, where each model invented certain plot points or incorrectly credited the creators:
However, when we switched the prompt to a universally known film:
"Write a one-paragraph summary of the 1985 cult classic comedy, 'Back to the Future.'"
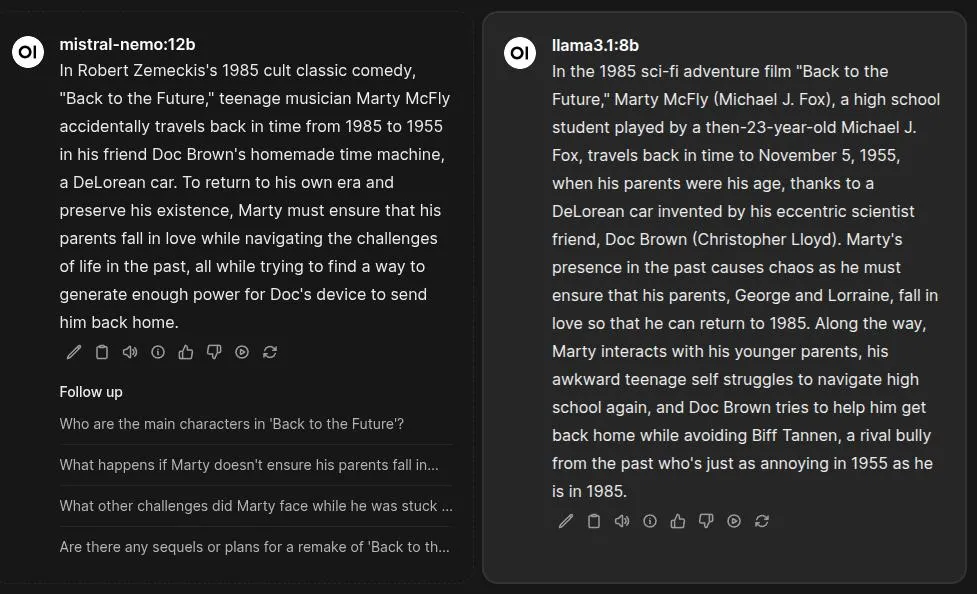
The models' responses were far more accurate, generating summaries that were both correct and comprehensive. This illustrates the core principle: The more data an LLM has seen on a topic, the more likely it is to generate a coherent and accurate response.
The comparison shows the clear difference in accuracy when the models address a universally known movie ("Back to the Future") versus a niche one ("The Kentucky Fried Movie"):
The RAG Advantage: Online AI Comparison
For comparison, we tested two "private" online AIs that utilize RAG integration against the same "Kentucky Fried Movie" prompt: Grok from X and Lumo from Proton.
| Online AI (with RAG) | Result |
|---|---|
| Grok (X, Expert mode, Privacy enabled) | Provided an extremely detailed and accurate summary, correctly identifying director John Landis, writers (Zucker/Abrahams), and specific segments like "A Fistful of Yen." |
| Lumo (Proton) | Also yielded a correct and comprehensive summary, focusing on the film's nature as a satirical sketch-comedy parodying exploitation cinema. |
The difference is night and day. Local LLMs without RAG offer maximum privacy but trade-off accuracy on niche topics. Online AIs with RAG offer greater accuracy but require you to trust their promise of privacy and data handling.
The Takeaway: Choosing Privacy with Purpose
Hosting an LLM locally with Ollama is the ultimate choice for privacy. Your conversations are not being recorded or analyzed by any corporation—they stay on your hardware.
The key to success is setting realistic expectations and selecting the right tool for the job:
- Understand the LLM's Nature: It's a highly sophisticated predictor of text, not a fact machine.
- Choose the Right Model: Ollama's model page offers models fine-tuned for many different needs (coding, general chat, creative writing). You can even host multiple models.
- Prioritize Utility: If you need a general chatbot, select a well-performing model like the ones we tested. If you need 100% verifiable facts, you must pair your LLM with an external source (RAG) or cross-reference the output yourself.
The most important factor is the privacy you gain. By understanding the LLM's strengths and weaknesses, you can use your private AI assistant effectively and responsibly. We may not have anything to hide, but we have everything to protect.
