Home Assistant Voice Translation: The Performance Upgrade

We’ve all been there: you embrace a new technology—you switch from an Amazon Echo to a Home Assistant server built on a spare Raspberry Pi, then add an Ollama server for advanced local voice AI. You’re thrilled to have a private, powerful smart home... until you ask it a simple question.
"How old is actor Kevin Bacon?"
...5-second delay.
"What famous airlines no longer exist?"
...6-second+ delay.
That's not a conversation; that's a coffee break.
When we rolled out our enhanced setup in April 2025, the lag was frustrating. The whole point was conversational intelligence, and a half-dozen second pause kills that experience. We had to ask: Where exactly was the bottleneck? This is the story of tracing that painful delay all the way back from the powerful Ollama server to the core of Home Assistant, making every component faster along the way.
1. Exonerating the AI: The Ollama Deep Dive
As with any good late-night debugging session, we started by targeting the most complex and powerful component: Ollama. Our voice pipeline looks like this:
Speech-to-Text → Query Ollama → Receive Response → Text-to-Speech
We connected directly to the Ollama server and fed it the transcribed text query. The results were immediate: most answers were generated within milliseconds. Ollama's raw text generation speed was not the problem.
The issue wasn't the total generation speed—it was the Time-to-First-Token (TTFT). The system struggled to load and initiate the model quickly, which translated to that painful upfront delay. To fix that, we needed to make the AI model itself an easier lift for the server.
Optimization: The Power of Quantization
Our first major breakthrough was a single, impactful change: moving from the original Llama 3.1 8B model to the highly compressed llama3.1:8b-instruct-q4_0.
This one switch delivered two key gains: Quantization (the speed boost) and Instruction-Tuning (the intelligence boost).
Quantization (Q4_0): Making Math Easier
We realized that even if the entire model could technically run, it wasn't optimized for our resource-constrained setup.
The Q4_0 model provides its speedup by simplifying the data required for every calculation. Instead of using complex 16-bit floating-point numbers (FP16), the model's weights were converted to simple 4-bit integers.
Original Data (FP16) → Quantized Data (Q4_0)
This is the technical magic that matters: we weren't just saving memory; we were making the processor’s job four times easier by giving it a simpler, faster form of data to compute. This dramatically accelerated the tokens-per-second inference speed and slashed the dreaded TTFT, making the initial response feel instantaneous.
Instruction-Tuning (Instruct): Smarter, Faster Answers
By using an Instruct version, we gained a model specifically fine-tuned for conversational and question-answering tasks. It is better aligned to understand commands like "How old is..." and provides more concise, relevant, and consistent answers. Fewer generated tokens to get the right answer means a faster overall experience.
2. Eliminating a Distraction: Network Speed
With the AI model now blazing fast, we looked at the next possible culprit: the network.
Both the Ollama server and the Home Assistant server were on the same network switch, so logic suggested they were communicating quickly. To eliminate all doubt, we checked the network interface on the Ollama server, setting its speed explicitly and disabling the autonegotiate feature.
The conclusion? Network performance was well within acceptable limits. The communication between the two servers was not the bottleneck. This led us to the last place to check—the very core of the smart home experience.
3. The True Culprit: The Home Assistant Hardware
We started our entire Home Assistant journey using a spare Raspberry Pi 4 Model B (4GB RAM). It worked fine for basic automation, but as the old truism goes: Nothing is so permanent as a temporary solution.
After all the configuration tweaking, prompt editing, and model optimization, we finally had to confront the simplest solution: throw hardware at the problem.
In true nerd fashion, a spare Raspberry Pi 5 8GB was gathering dust. The Pi 5 represents a significant generational leap in capability over the Pi 4, with a massive performance upgrade and faster I/O.
The Home Assistant Upgrade
We flashed a new SD card, loaded it into the Raspberry Pi 5, restored the current configuration, and held our breath for the moment of truth.
Our reliable 5 to 6-second test question: "What's the capital of France?"
New Response Time: Under 2 seconds!
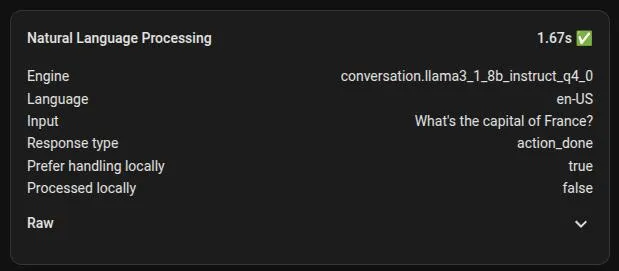
The performance of the Home Assistant system itself was the final, and largest, bottleneck. By upgrading the core hardware, several parts of the voice pipeline saw dramatic improvements:
- Intent Determination: The time it takes to figure out if the user is giving a command or asking a question was reduced.
- API Calls: Home Assistant's communication with the now-optimized Ollama server was faster.
- Text-to-Speech Generation: The final step of turning the AI's answer back into audio was faster.
Every step of this performance journey led to a dramatic improvement, with voice responses being the most outwardly noticeable gain.
The best part? All processing happens locally. We now have a truly conversational, lightning-fast, and completely private voice assistant, proving that with a little digging, you don't have to sacrifice user experience for privacy.
Remember, we may not have anything to hide, but everything to protect.
